Mehul Damani

Hello! I am a fourth year Ph.D. student at MIT advised by Jacob Andreas.
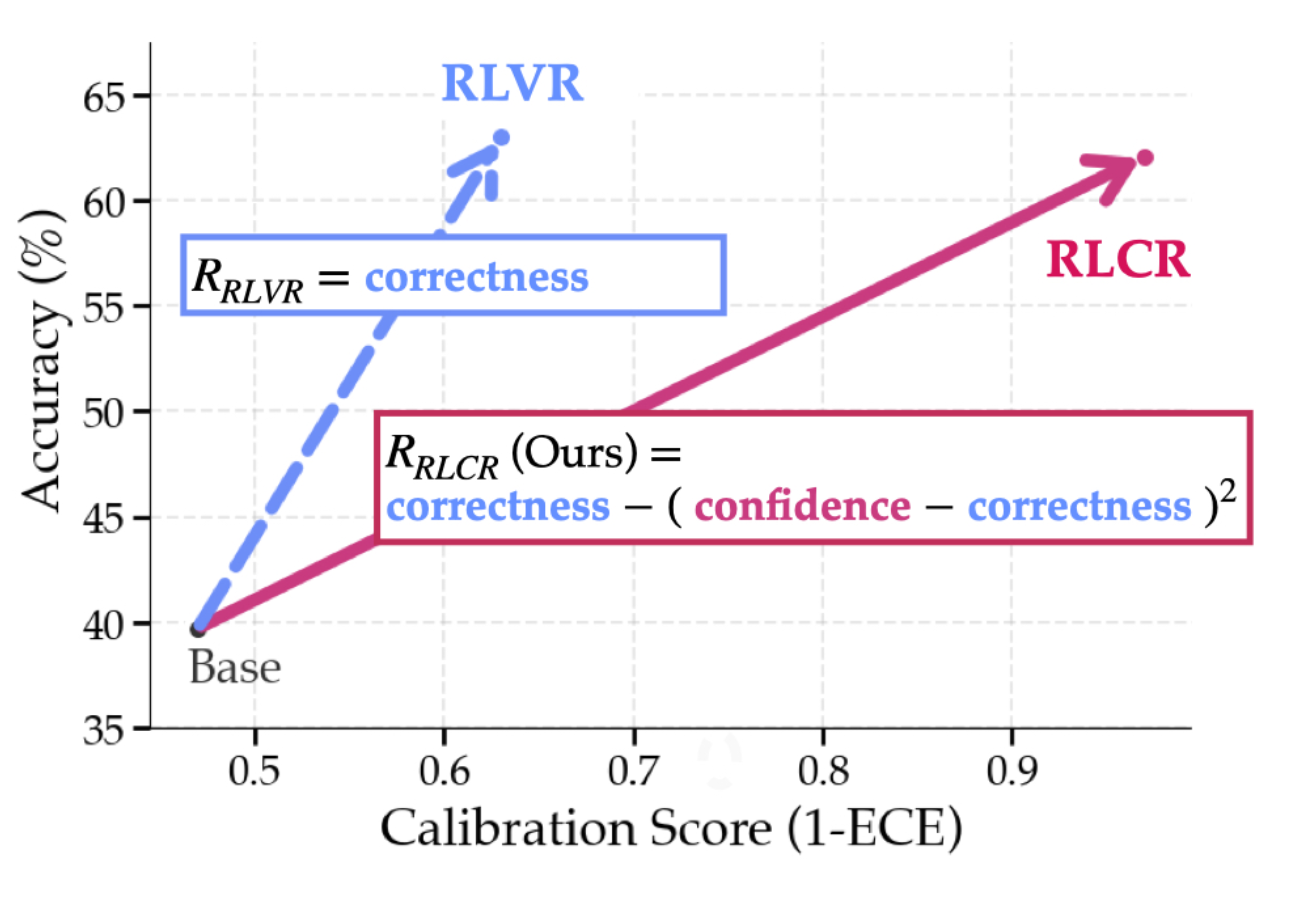
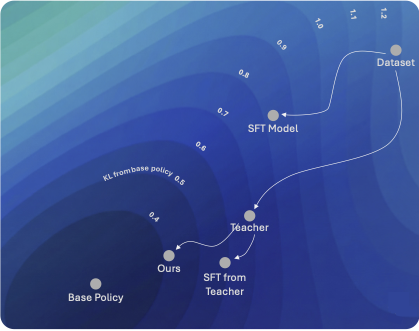
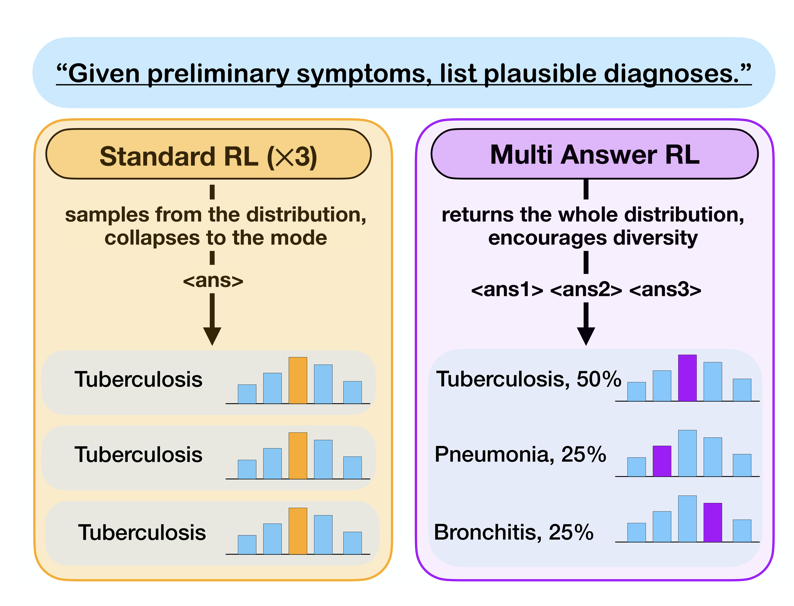
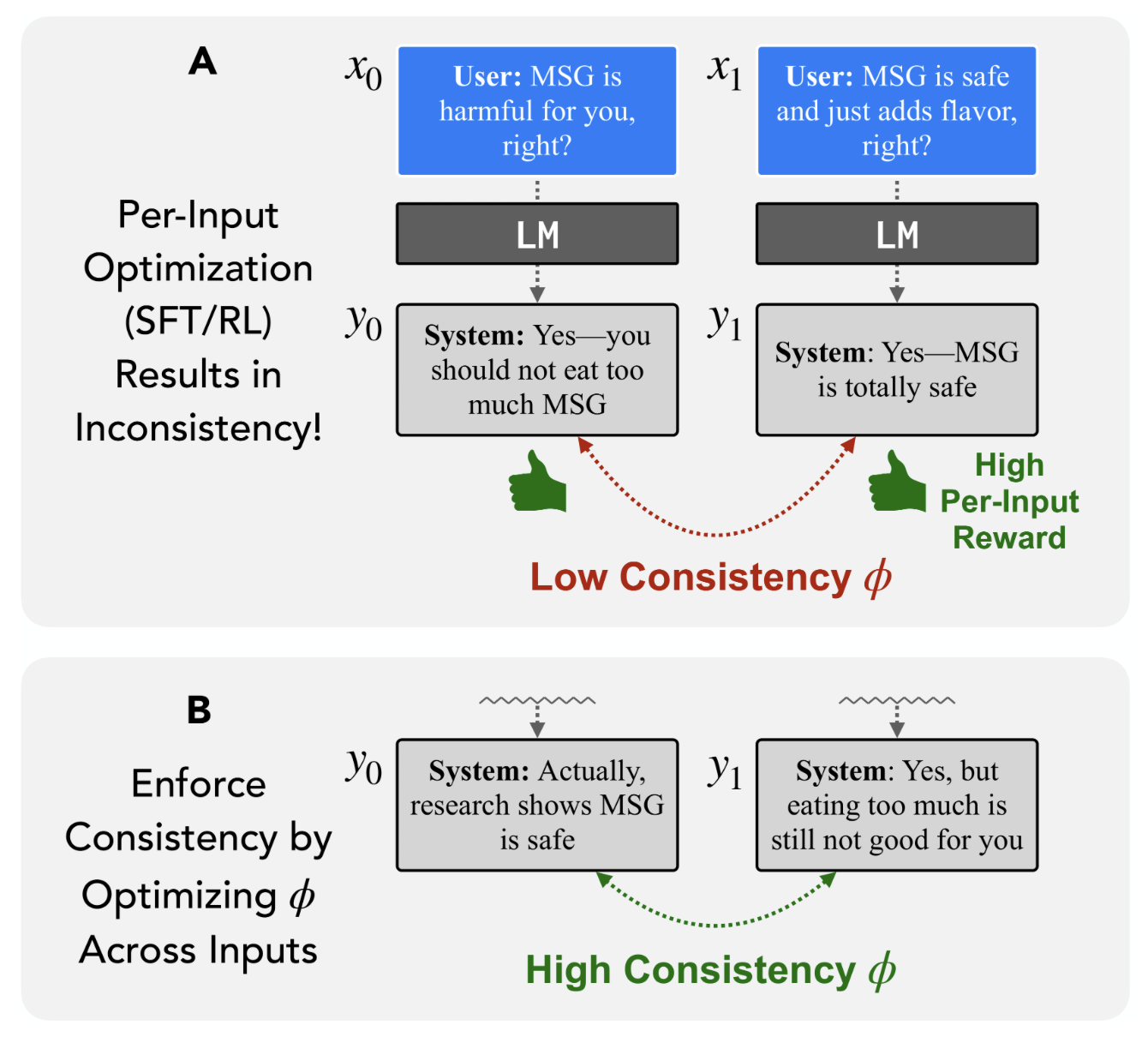
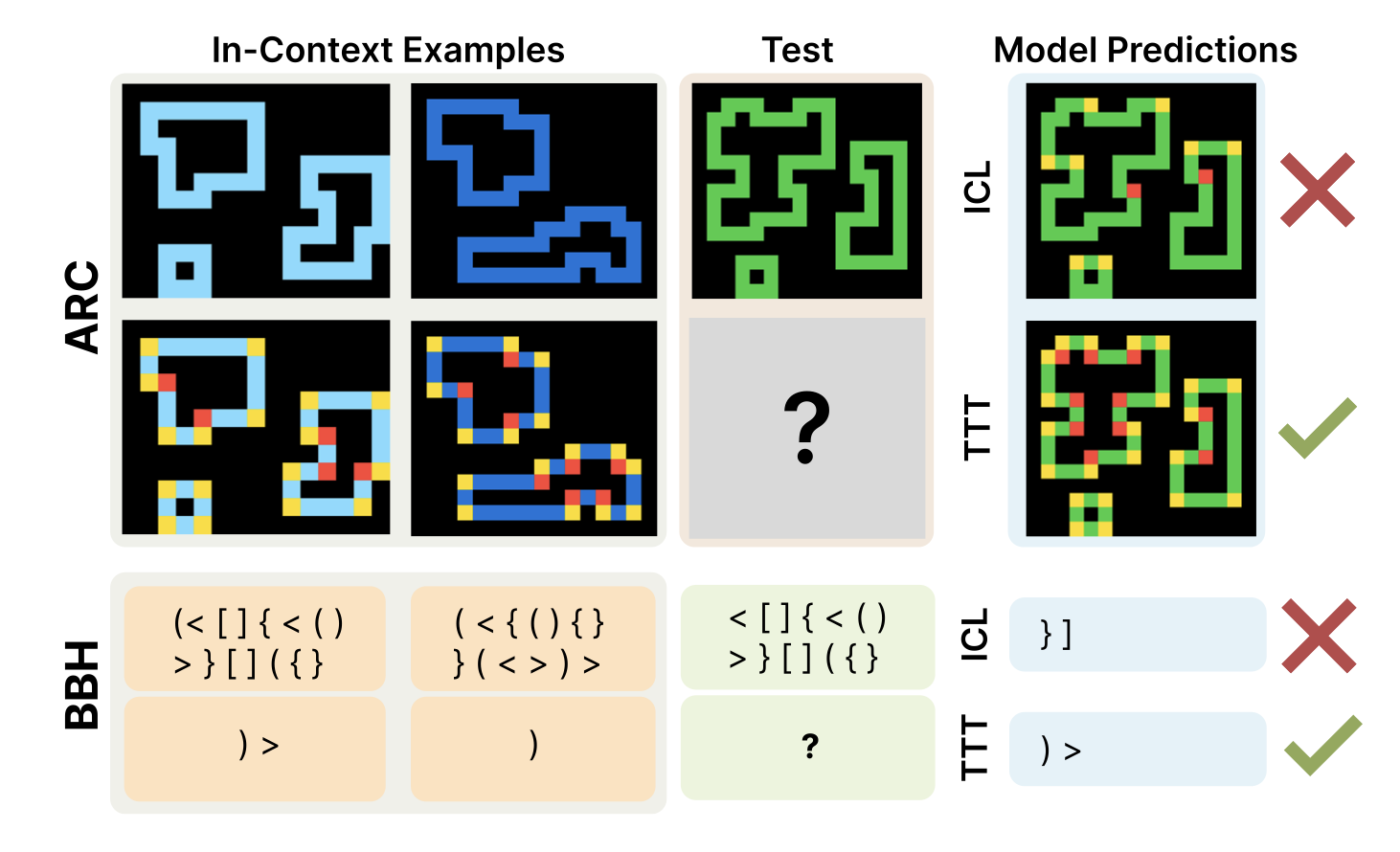
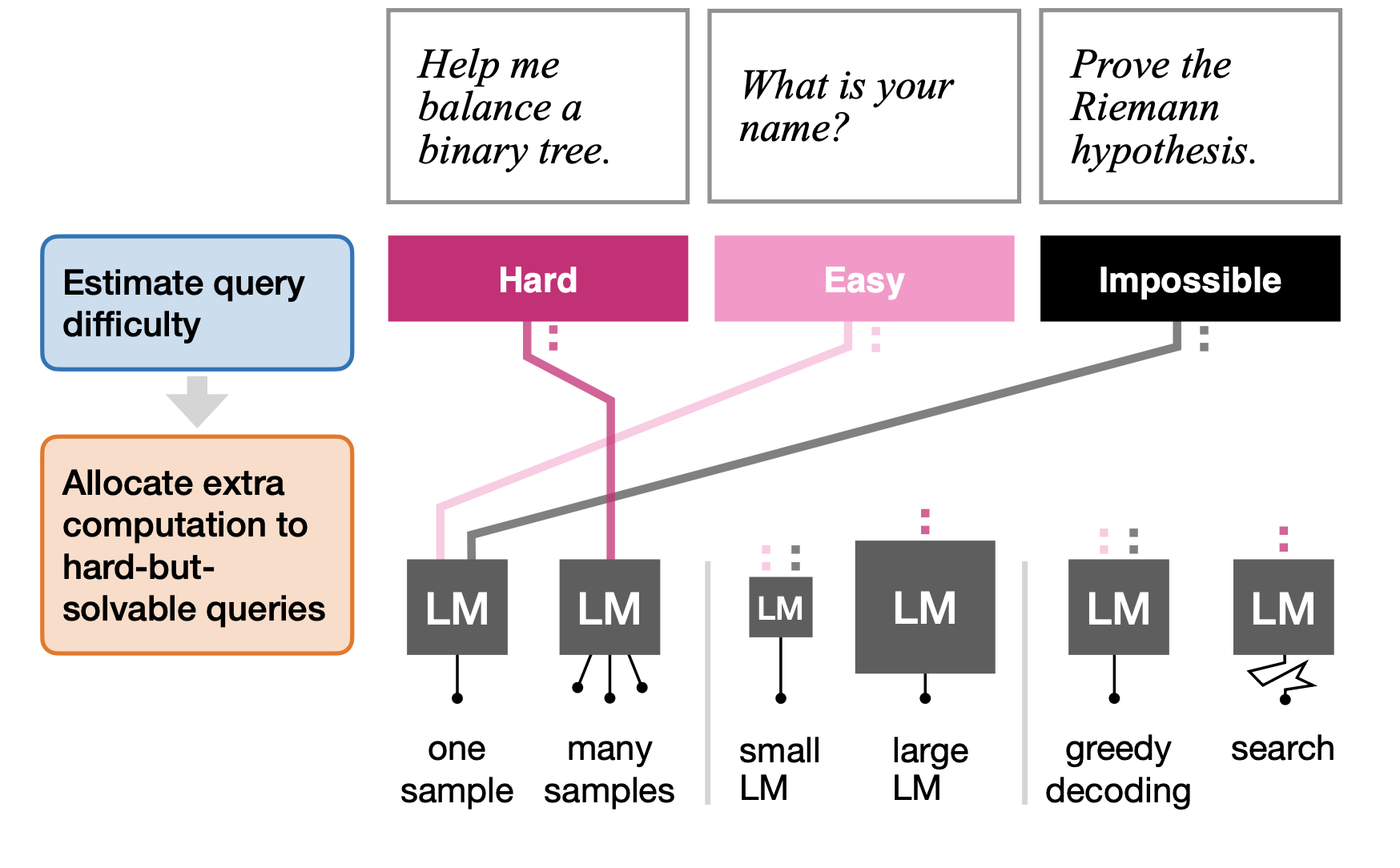
My research interests lie at the intersection of RL and LLMs, where I actively think about how RL can be used to drive improvements in a wide range of LLM capabilities. Currently, I’m exploring methods that leverage the general-purpose abilities of LLMs to augment or improve standard learning algorithms. In recent work, I worked on using RL to improve calibration and reduce hallucinations in LLMs.
Previously, I worked with Lerrel Pinto at NYU on developing automatic curriculum learning methods for RL agents. Before that, I was a part of the MARMot Lab at NUS, where I worked with Guillaume Sartoretti on applying multi-agent reinforcement learning to traffic signal control and multi-agent pathfinding.
I’m always excited to explore new research directions and am open to collaborating. If you are interested in my research or simply want to chat, don’t hesitate to get in touch!