publications
2026
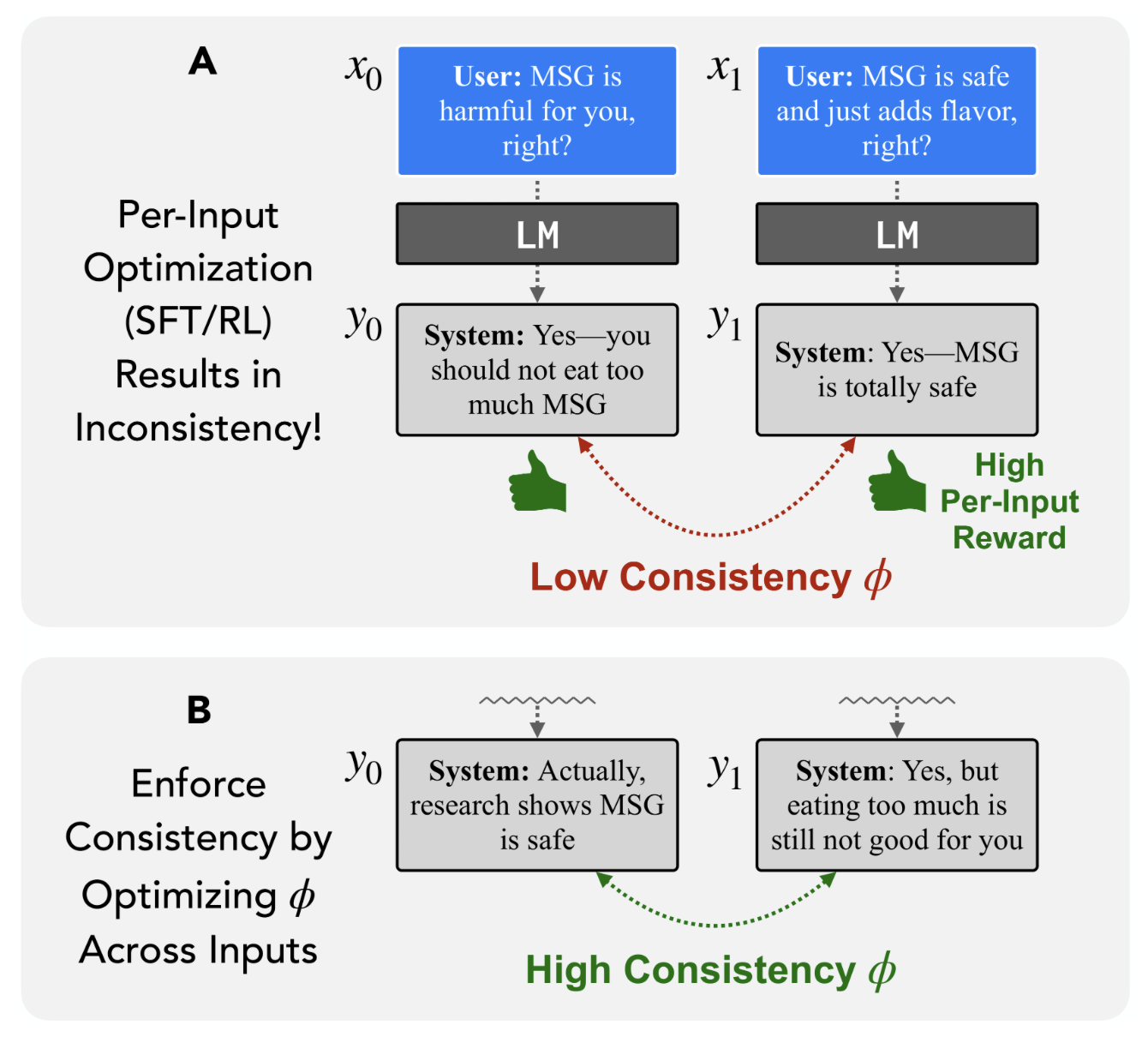 Position: It's Time to Optimize for Self-ConsistencyItamar Pres, Belinda Z. Li, Laura Ruis, Zifan Carl Guo, Keya Hu, Mehul Damani, Isha Puri, Ekdeep Singh Lubana, and Jacob Andreas
Position: It's Time to Optimize for Self-ConsistencyItamar Pres, Belinda Z. Li, Laura Ruis, Zifan Carl Guo, Keya Hu, Mehul Damani, Isha Puri, Ekdeep Singh Lubana, and Jacob Andreas
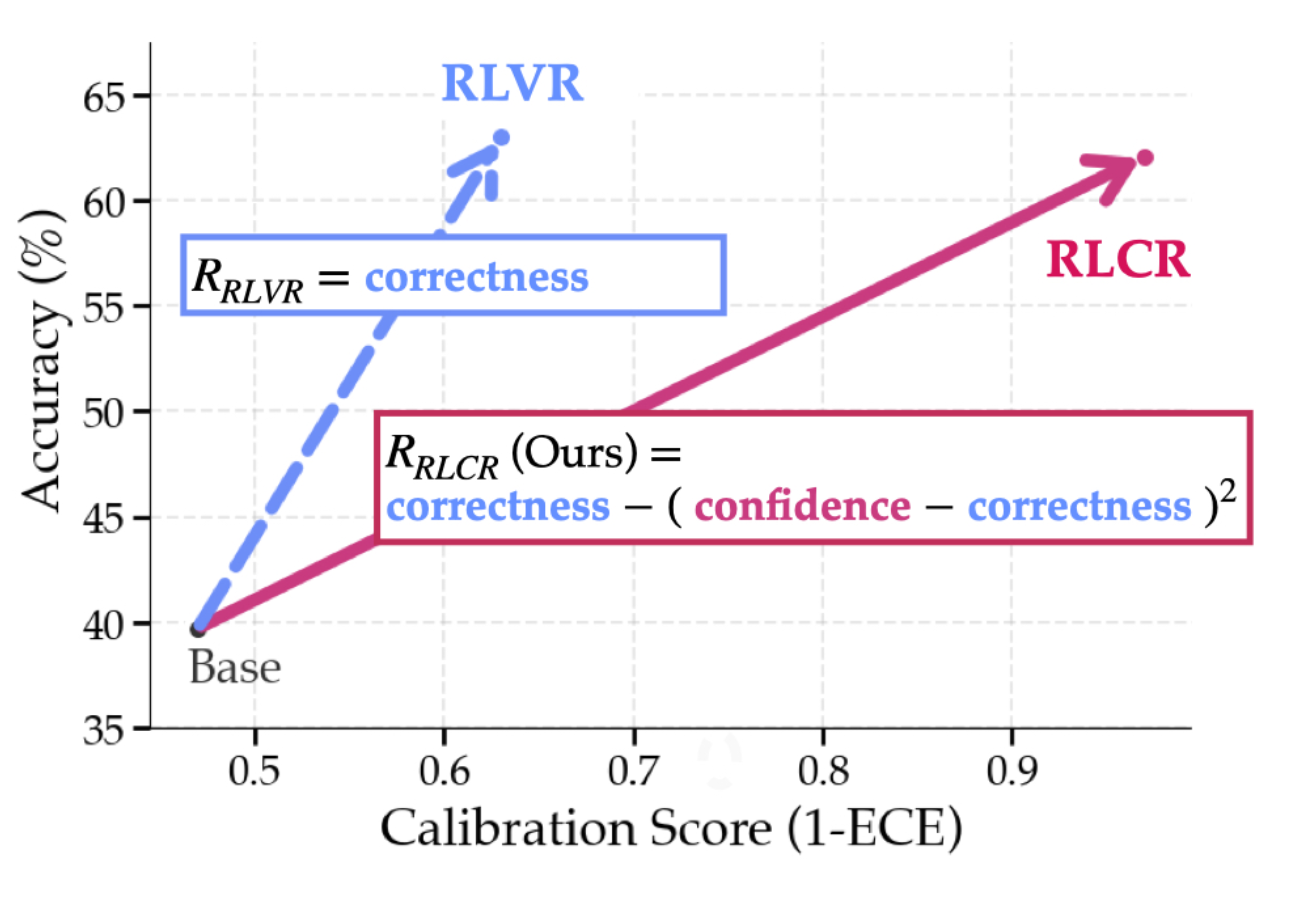
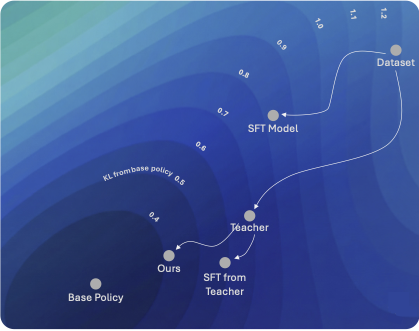
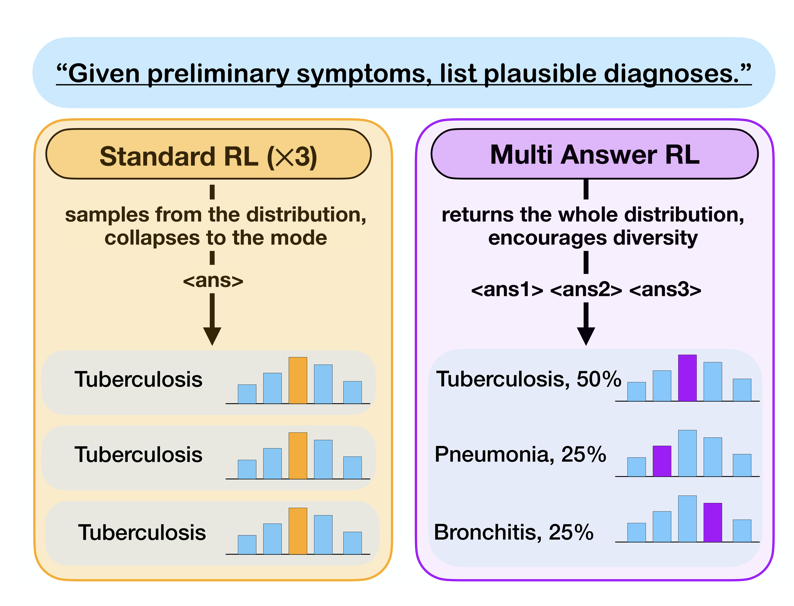
2025
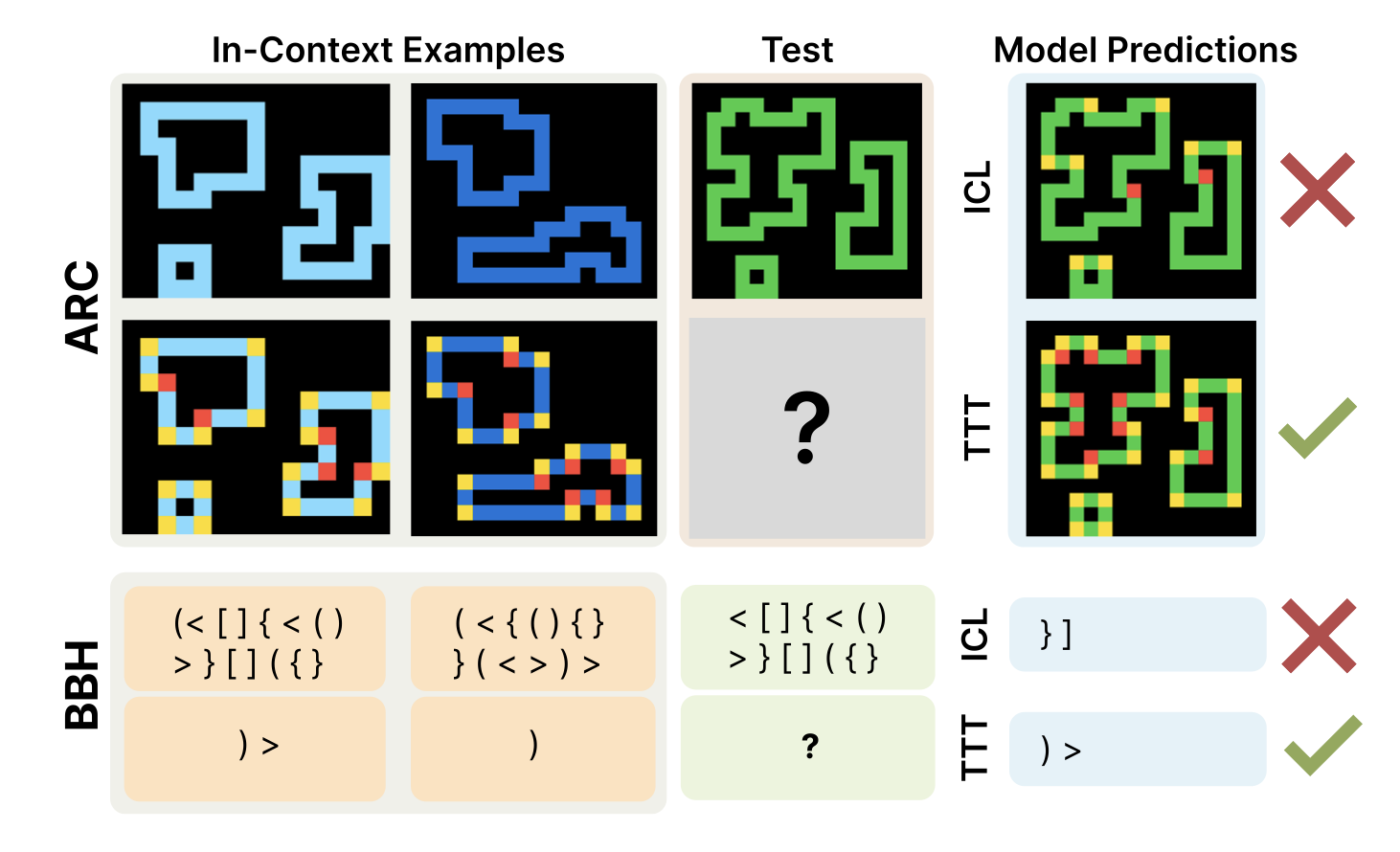 The Surprising Effectiveness of Test-Time Training for Few-Shot LearningICML, 2025Ekin Akyürek, Mehul Damani, Adam Zweiger, Linlu Qiu, Han Guo, Jyo Pari, Yoon Kim, and Jacob Andreas
The Surprising Effectiveness of Test-Time Training for Few-Shot LearningICML, 2025Ekin Akyürek, Mehul Damani, Adam Zweiger, Linlu Qiu, Han Guo, Jyo Pari, Yoon Kim, and Jacob Andreas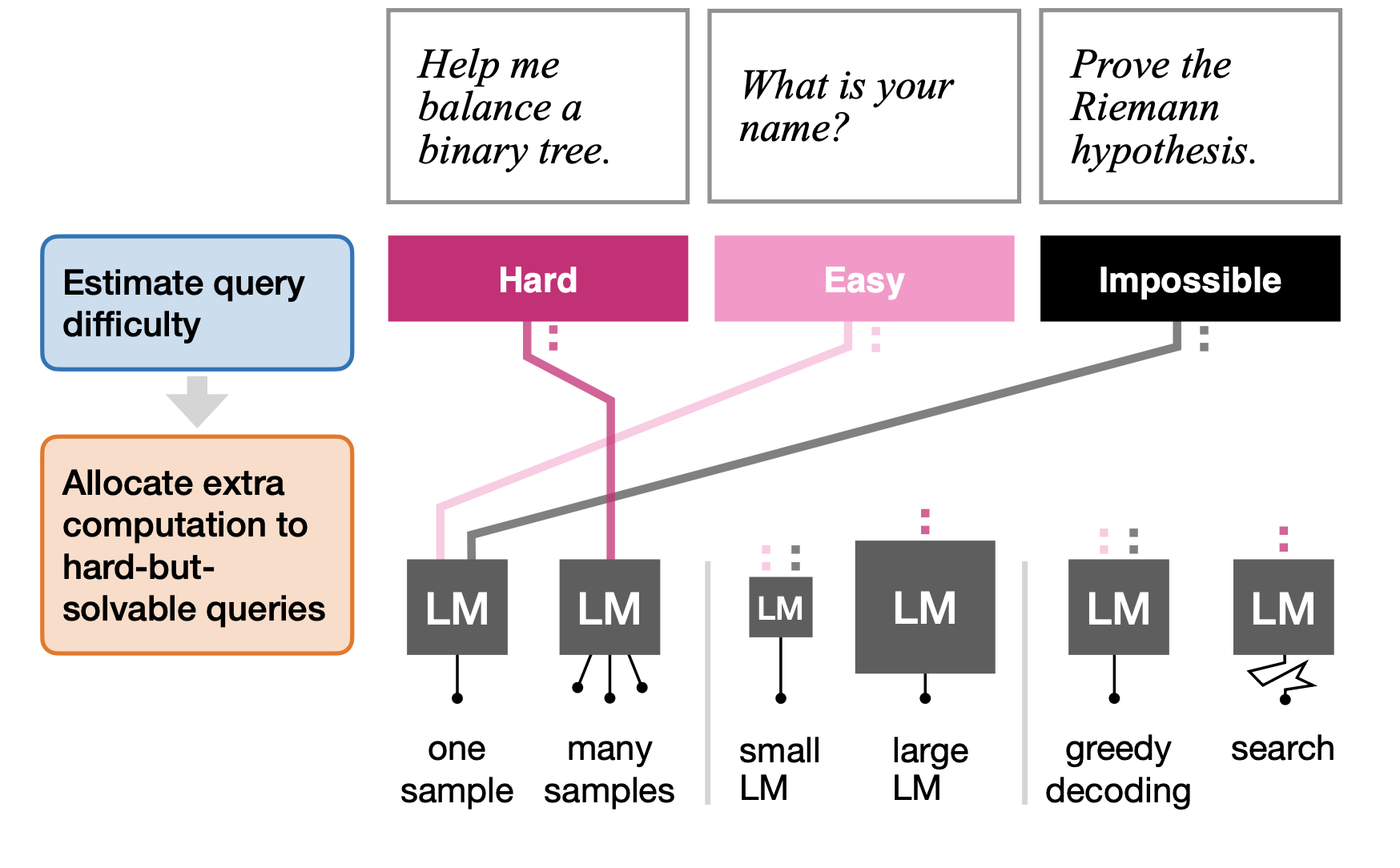 Learning How Hard to Think: Input-Adaptive Allocation of LM ComputationICLR, 2025Mehul Damani, Idan Shenfeld, Andi Peng, Andreea Bobu, and Jacob Andreas
Learning How Hard to Think: Input-Adaptive Allocation of LM ComputationICLR, 2025Mehul Damani, Idan Shenfeld, Andi Peng, Andreea Bobu, and Jacob Andreas
2024
 Formal contracts mitigate social dilemmas in multi-agent reinforcement learningAAMAS, 2024Andreas Haupt, Phillip Christoffersen, Mehul Damani, and Dylan Hadfield-Menell
Formal contracts mitigate social dilemmas in multi-agent reinforcement learningAAMAS, 2024Andreas Haupt, Phillip Christoffersen, Mehul Damani, and Dylan Hadfield-Menell
2023
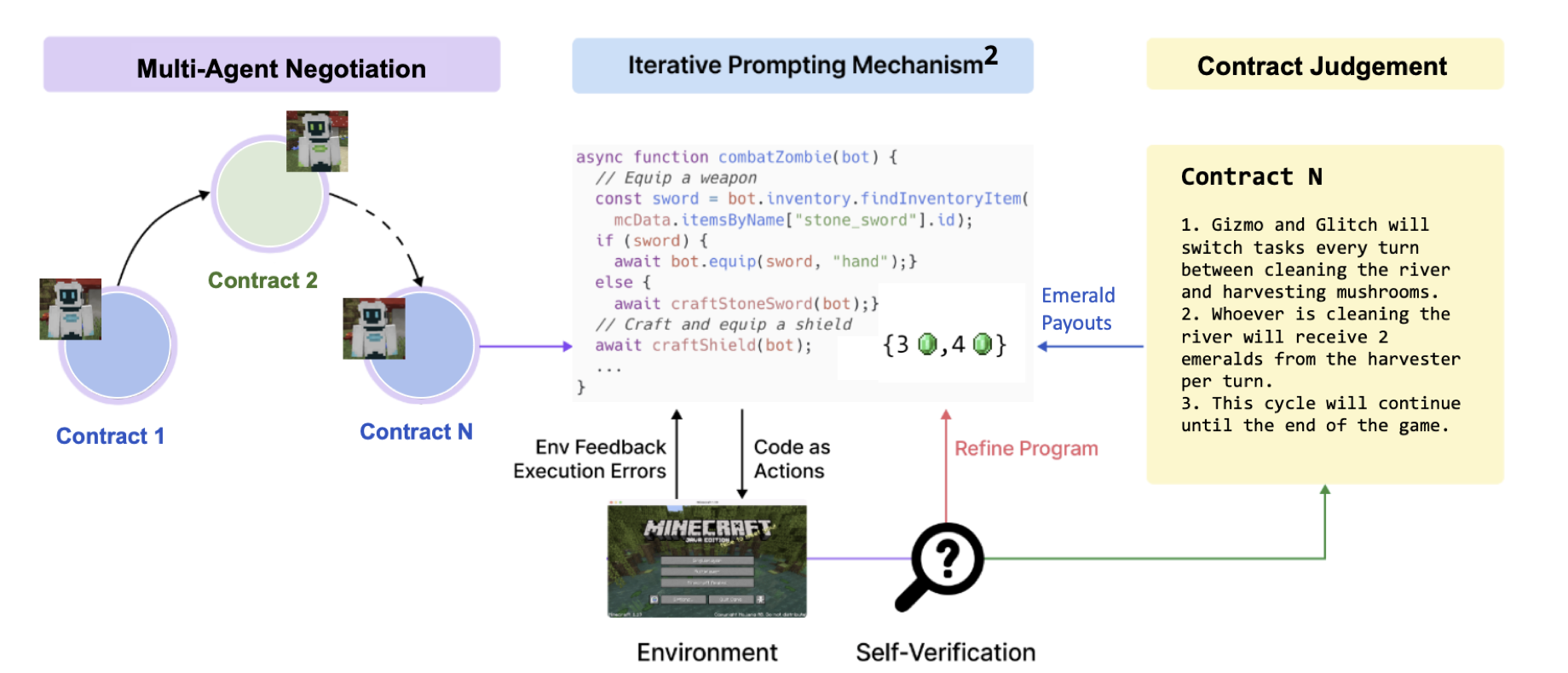 Mitigating Generative Agent Social DilemmasNeurIPS 2023 Foundation Models for Decision Making WorkshopJulian Yocum, Phillip Christoffersen, Mehul Damani, Justin Svegliato, Dylan Hadfield-Menell, and Stuart Russell
Mitigating Generative Agent Social DilemmasNeurIPS 2023 Foundation Models for Decision Making WorkshopJulian Yocum, Phillip Christoffersen, Mehul Damani, Justin Svegliato, Dylan Hadfield-Menell, and Stuart Russell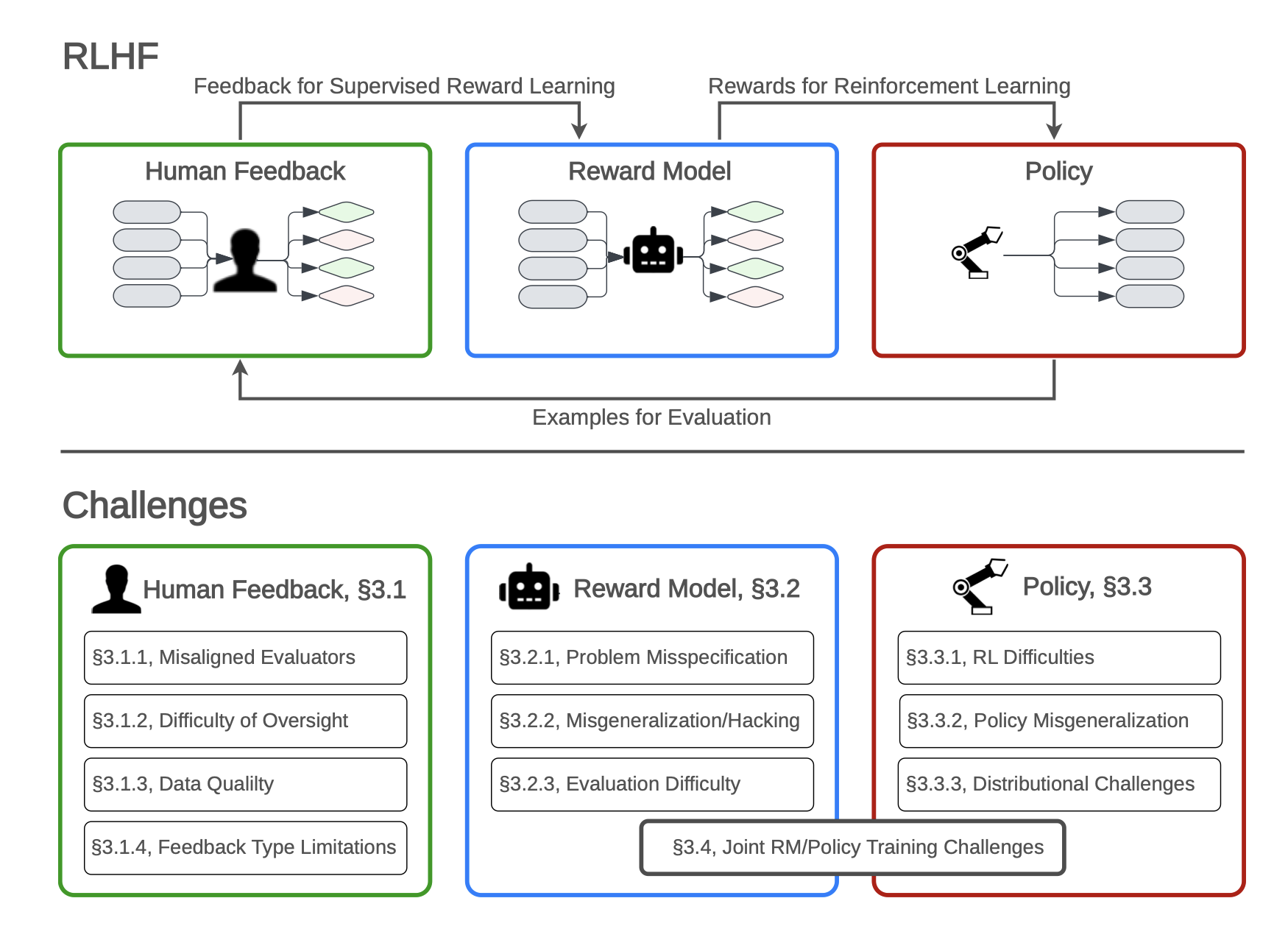 Open Problems and Fundamental Limitations of Reinforcement Learning from Human FeedbackTransactions on Machine Learning ResearchStephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jeremey Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, Tony Tong Wang, Samuel Marks, Charbel-Raphael Segerie, Micah Carroll, Andi Peng, Phillip Christoffersen, Mehul Damani, Stewart Slocum, Usman Anwar, Anand Siththaranjan, Max Nadeau, Eric J Michaud, Jacob Pfau, Dmitrii Krasheninnikov, Xin Chen, Lauro Langosco, Peter Hase, Erdem Biyik, Anca Dragan, David Krueger, Dorsa Sadigh, and Dylan Hadfield-Menell
Open Problems and Fundamental Limitations of Reinforcement Learning from Human FeedbackTransactions on Machine Learning ResearchStephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jeremey Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, Tony Tong Wang, Samuel Marks, Charbel-Raphael Segerie, Micah Carroll, Andi Peng, Phillip Christoffersen, Mehul Damani, Stewart Slocum, Usman Anwar, Anand Siththaranjan, Max Nadeau, Eric J Michaud, Jacob Pfau, Dmitrii Krasheninnikov, Xin Chen, Lauro Langosco, Peter Hase, Erdem Biyik, Anca Dragan, David Krueger, Dorsa Sadigh, and Dylan Hadfield-Menell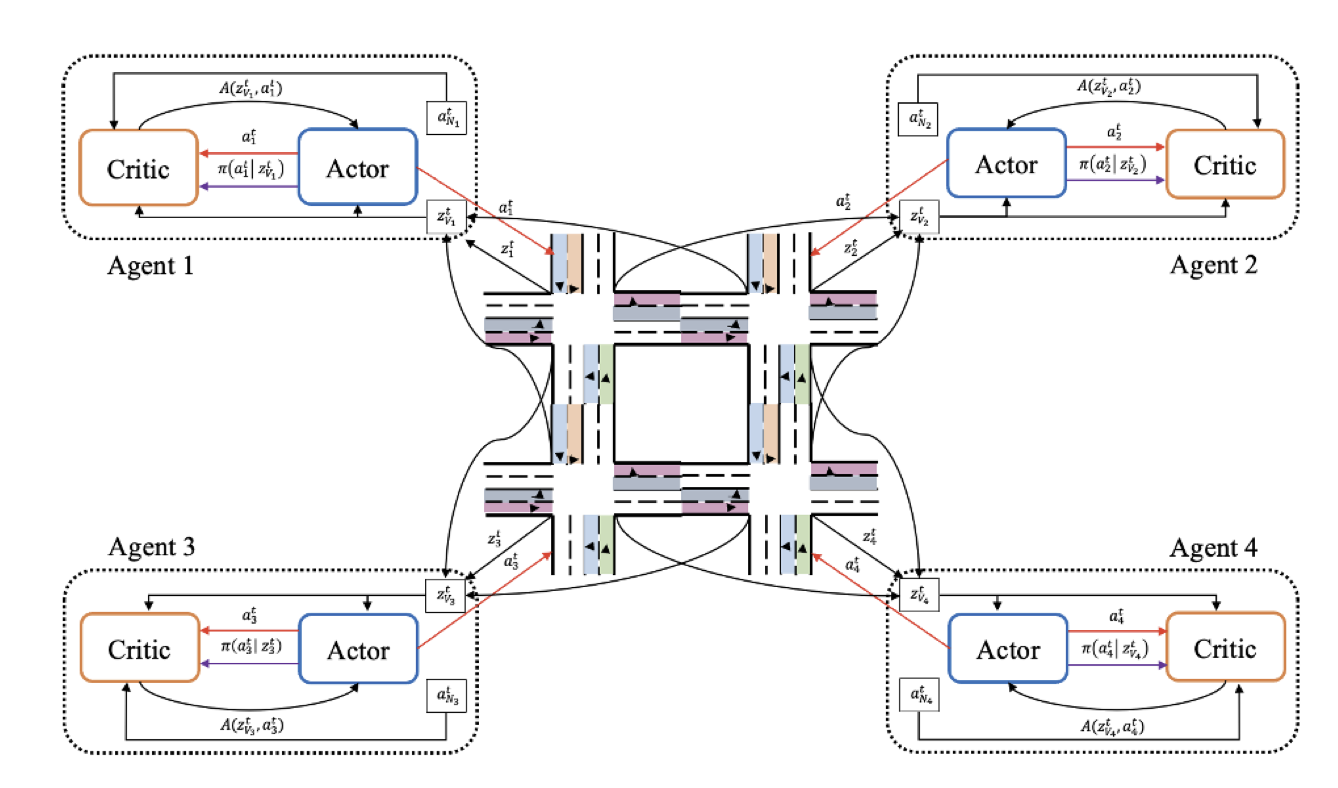 SocialLight: Distributed Cooperation Learning towards Network-Wide Traffic Signal ControlProceedings of the 2023 International Conference on Autonomous Agents and Multiagent SystemsHarsh Goel, Yifeng Zhang, Mehul Damani, and Guillaume Sartoretti
SocialLight: Distributed Cooperation Learning towards Network-Wide Traffic Signal ControlProceedings of the 2023 International Conference on Autonomous Agents and Multiagent SystemsHarsh Goel, Yifeng Zhang, Mehul Damani, and Guillaume SartorettiMany recent works have turned to multi-agent reinforcement learning (MARL) for adaptive traffic signal control to optimize the travel time of vehicles over large urban networks. However, achieving effective and scalable cooperation among junctions (agents) remains an open challenge, as existing methods often rely on extensive, non-generalizable reward shaping or on non-scalable centralized learning. To address these problems, we propose a new MARL method for traffic signal control, SocialLight, which learns cooperative traffic control policies by distributedly estimating the individual marginal contribution of agents on their local neighborhood. SocialLight relies on the Asynchronous Actor Critic (A3C) framework, and makes learning scalable by learning a locally-centralized critic conditioned over the states and actions of neighboring agents, used by agents to estimate individual contributions by counterfactual reasoning. We further introduce important modifications to the advantage calculation that help stabilize policy updates. These modifications decouple the impact of the neighbors' actions on the computed advantages, thereby reducing the variance in the gradient updates. We benchmark our trained network against state-of-the-art traffic signal control methods on standard benchmarks in two traffic simulators, SUMO and CityFlow. Our results show that SocialLight exhibits improved scalability to larger road networks and better performance across usual traffic metrics.
2022
 Distributed Reinforcement Learning for Robot Teams: a ReviewCurrent Robotics ReportsYutong Wang, Mehul Damani, Pamela Wang, Yuhong Cao, and Guillaume Sartoretti
Distributed Reinforcement Learning for Robot Teams: a ReviewCurrent Robotics ReportsYutong Wang, Mehul Damani, Pamela Wang, Yuhong Cao, and Guillaume SartorettiRecent advances in sensing, actuation, and computation have opened the door to multi-robot systems consisting of hundreds/thousands of robots, with promising applications to automated manufacturing, disaster relief, harvesting, last-mile delivery, port/airport operations, or search and rescue. The community has leveraged model-free multi-agent reinforcement learning (MARL) to devise efficient, scalable controllers for multi-robot systems (MRS). This review aims to provide an analysis of the state-of-the-art in distributed MARL for multi-robot cooperation.
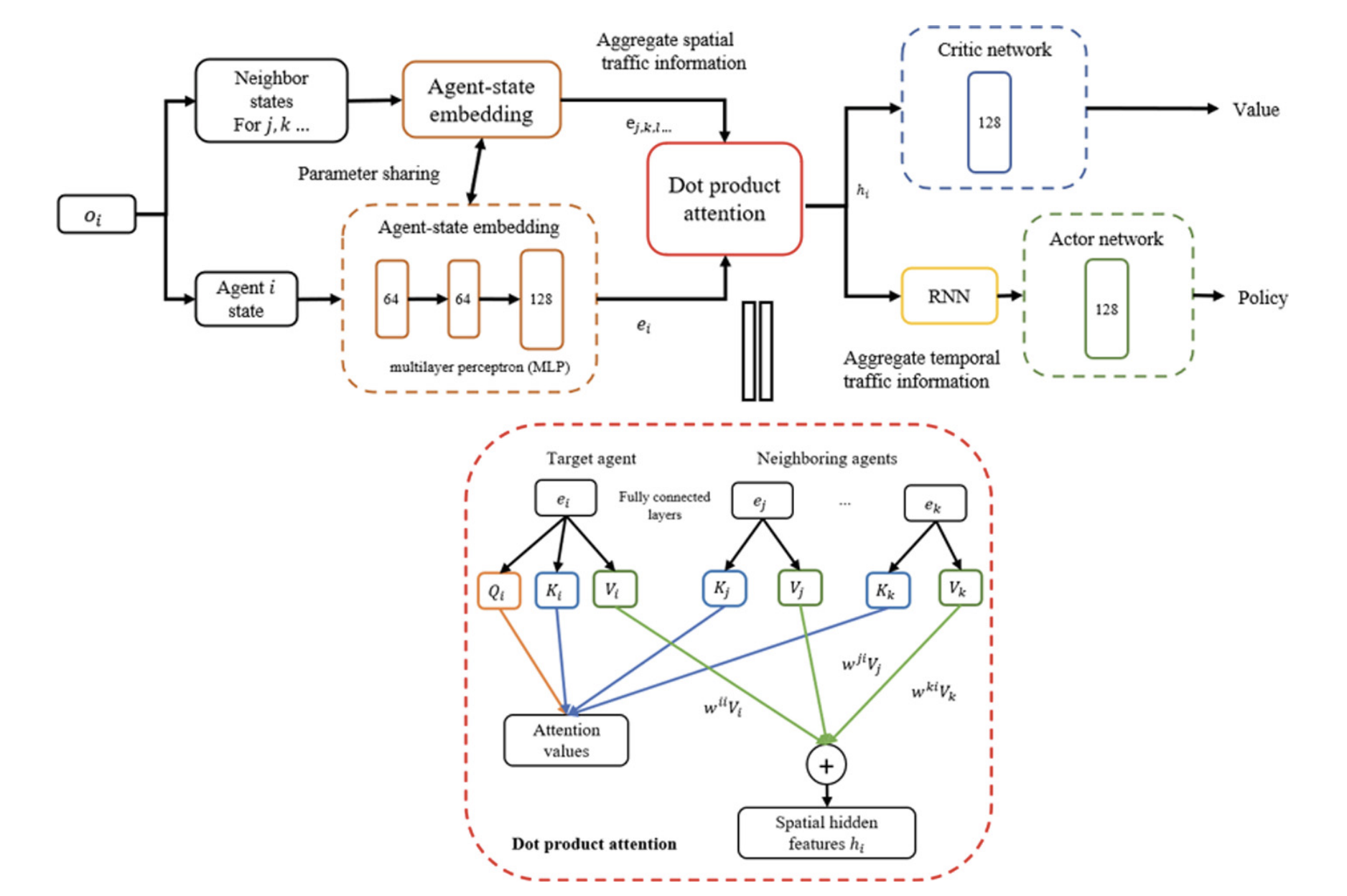 Multi-Agent Traffic Signal Control via Distributed RL with Spatial and Temporal Feature ExtractionInternational Workshop on Agent-Based Modelling of Urban Systems (ABMUS)Yifeng Zhang, Mehul Damani, and Guillaume Sartoretti
Multi-Agent Traffic Signal Control via Distributed RL with Spatial and Temporal Feature ExtractionInternational Workshop on Agent-Based Modelling of Urban Systems (ABMUS)Yifeng Zhang, Mehul Damani, and Guillaume Sartoretti
2021
 Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid WorldProceedings of the NeurIPS 2020 Competition and Demonstration TrackFlorian Laurent, Manuel Schneider, Christian Scheller, Jeremy Watson, Jiaoyang Li, Zhe Chen, Yi Zheng, Shao-Hung Chan, Konstantin Makhnev, Oleg Svidchenko, Vladimir Egorov, Dmitry Ivanov, Aleksei Shpilman, Evgenija Spirovska, Oliver Tanevski, Aleksandar Nikov, Ramon Grunder, David Galevski, Jakov Mitrovski, Guillaume Sartoretti, Zhiyao Luo, Mehul Damani, Nilabha Bhattacharya, Shivam Agarwal, Adrian Egli, Erik Nygren, and Sharada Mohanty
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid WorldProceedings of the NeurIPS 2020 Competition and Demonstration TrackFlorian Laurent, Manuel Schneider, Christian Scheller, Jeremy Watson, Jiaoyang Li, Zhe Chen, Yi Zheng, Shao-Hung Chan, Konstantin Makhnev, Oleg Svidchenko, Vladimir Egorov, Dmitry Ivanov, Aleksei Shpilman, Evgenija Spirovska, Oliver Tanevski, Aleksandar Nikov, Ramon Grunder, David Galevski, Jakov Mitrovski, Guillaume Sartoretti, Zhiyao Luo, Mehul Damani, Nilabha Bhattacharya, Shivam Agarwal, Adrian Egli, Erik Nygren, and Sharada MohantyThe Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
